Linux is more secure than Windows and this is no secret. Many websites and companies alike all use Linux for their servers. Some Linux desktops are more stable than others that is true, but Linux servers have fewer attack surfaces thanks to the headless(lack of desktop) by default set up. Linux servers are sturdy as there is no graphical interfaces or other useless software getting in the way. Linux servers are, in my opinion, far superior to Windows servers. This is much to do with the lack of graphical tools as well as how the system is laid out by default. Linux files are placed in order on the drive, whereas a Windows machine is constantly in complete chaos. Always moving files around to and fro. In Linux, the file system is structured in a much more organized fashion.
Another way that Linux is more secure and better than Windows is that Linux uses separate accounts in Ubuntu by default. Manjaro is generally used in a similar way. Arch and Debian usually have it differently, one could argue this way is actually better, but it is more restrictive. In Debian, I have to log into root to install something, yet I can still use software from the standard user account. This isn’t remotely set up by default in Windows. This means that files and programs can only access what the user has access to while the user is running the program.
Linux security depends on the file being executable, this goes back to the filesystem in that files aren’t generally executable by default, this would cause memory and cpu issues, it would mean that any file could run rampant. Writing software for Linux is a different process than for Windows. In Windows, files are typically set to executable by default and this is by design. Windows is meant to be easily accessible, probably so much so that there are more viruses targeting it as a whole. File extensions also prohibit Windows viruses from running within Linux systems as Linux doesn’t have equivalent extensions. Linux itself isn’t the Operating System, contrary to everyone’s believe, it is the kernel, however, the kernel is audited every day by thousands/hundreds of thousands of people worldwide.
Most of the software on top of the Linux kernel is open-source. Open-source means that it is easily viewable as well. Every line of code can be read and accounted for. Many can’t read code, however, this doesn’t stop the many talented geeks who can. Generally this software is free, but regardless of the monetary status, Linux is open while Windows is behind closed doors.Windows is generally shut off from third party auditing. Also, unlike Windows, there is no telemetry collection either. This is something that is quickly becoming popular with computer users across the globe.
Lastly, Linux has exceptional tools for monitoring and intrusion detection(Tripwire, snort, etc). It’s no wonder why so many companies and website owners use it for their backend. Linux market share is rising on the desktop slightly as well. While it still has a way to go before it’s targeted so widely as Windows, it still shows promise, and what can be accomplished with open-source software. Moving forward, we should expect to see it prosper and bloom. Linux is the future.
Shameless Plug: https://github.com/jackrabbit335/UsefulLinuxShellScripts
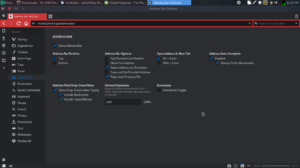
 and go to Tools > Settings. The Settings dialogue pops up with various settings. Each configuration has its own separate tab. Themes, Appearance, Start Page, etc. Under appearance, I usually check the box that allows settings to open in a new tab.
and go to Tools > Settings. The Settings dialogue pops up with various settings. Each configuration has its own separate tab. Themes, Appearance, Start Page, etc. Under appearance, I usually check the box that allows settings to open in a new tab. 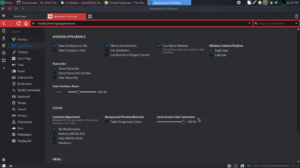 This will make settings take a full page next time. If you want performance over crazy effects and features, the settings tab under Appearance might also have benefits for you, This tab also lets you set or unset animations and use native window management(Adds a native looking border around window). This might be helpful on lower spec systems. Also disabling fast forward buttons in address bar might help as well.
This will make settings take a full page next time. If you want performance over crazy effects and features, the settings tab under Appearance might also have benefits for you, This tab also lets you set or unset animations and use native window management(Adds a native looking border around window). This might be helpful on lower spec systems. Also disabling fast forward buttons in address bar might help as well.